2016年度 発展プログラミング演習 第10講 Findプログラム 4日目
本日の内容
9. 文字列検索を高速に実施できるようにする.
9-1. 単純な文字列検索
前回のプログラムでは,8-3において,
grepオプションの実装を行いました.
そこでは,ある文字列から特定の文字列が含まれているかをcontains
メソッドで確認しました.このcontainsメソッドの中では,
どのようなことを行っているのかを確認してみましょう.
これらのプログラムを実際に書くことは少ないですが, どのような処理が行われていることの理解は非常に重要です.
String型は,文字型であるCharacter型のリストを内部に保持しています.
そこで,Character型のリストを使ってcontains
メソッドを実際に作成してみましょう.
public class StringSearcher{
void run(String[] args){
List<Character> chars1 = this.getChars(args[0]);
List<Character> chars2 = this.getChars(args[1]);
Boolean contain = this.contains(chars1, chars2);
System.out.printf(
"%s.contains(%s): %s%n", args[0],
args[1], contain
);
}
Boolean contains(List<Character> list1,
List<Character> list2){
// ここの処理を実際に書いてみる.
}
Boolean checkSubsequence(List<Character> list1,
List<Character> list2,
Integer begin){
// n回目の照合を行うためのメソッド.
}
// 文字列の要素となる文字型の値を List に入れて返す.
List<Character> getChars(String string){
List<Character> list = new ArrayList<Character>();
for(Integer i = 0; i < string.length(); i++){
list.add(string.charAt(i));
}
return list;
}
// mainメソッドは省略.
}
つまりは,左のプログラムのcontainsメソッドの内部を書いてみましょう.
ここで,2つのString型の値を考えましょう.検索対象となる文字列(検索対象文字列)が
"string1"とし,検索対象から検索する文字(照合文字列)を
"ring"とします.
これらの文字列は,String型の値として扱われます.
 しかし,内部的には,これらの値は配列として扱われています.
このとき,
しかし,内部的には,これらの値は配列として扱われています.
このとき,"string1"の中に"ring"
が含まれているかをどのようにプログラムで判定すれば良いのかを考えましょう.
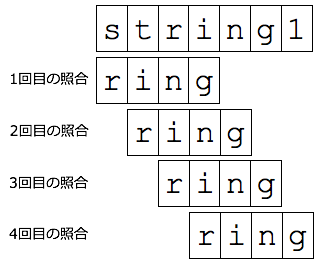 単純に考えれば,先頭位置をずらして,順番に照合し,見つかったところで成功と返すのが良いでしょう.
右図では,
単純に考えれば,先頭位置をずらして,順番に照合し,見つかったところで成功と返すのが良いでしょう.
右図では,"string1"を固定し,照合文字列である
"ring"
の位置を順にずらしています.そして,3回目の照合でマッチすることがわかります.
このように単純な方法ですが, この方法を実際にプログラミングで書いてみましょう.
-
containsメソッドでは次の処理を行ってください.-
Inetger型のlength変数を宣言しましょう. 初期値は,list1.size() - list2.size() + 1とします. この値は,何回照合を行うかの回数を示しています. -
0からlengthまで繰り返し処理を書いてください. 繰り返し処理の中では次の処理を行います. -
checkSubsequenceメソッドを呼び出してください.checkSubsequenceには,list1,list2,そして,ループの制御変数を渡してください. -
checkSubsequenceがtrueを返せば,trueを返しましょう. -
checkSubsequenceがfalseを返せば, そのままループを続けてください. - ループが終了すれば
falseを返しましょう.
-
-
checkSubsequenceメソッドはn回目の照合を行うメソッドとして定義します.0からlist2.size()まで繰り返しを行います.-
繰り返しの中では,検索対象文字列と,照合文字列からそれぞれ1文字取り出し比較しましょう.
取り出す文字は次の通りです.それぞれのループで,どの値が比較されているのかを考えましょう.
- 検索対象文字列(
list1) から取り出すインデックスは引数で受け取ったInteger型の値とループ制御変数の加算値です. - 照合文字列(
list2)から取り出すインデックスは,ループ制御変数です.
- 検索対象文字列(
- 取り出した2つの文字が一致しなければ,
falseを返してください. - ループが終われば,
trueを返しましょう.
9-2. 処理時間の計測方法.
ここでは,処理時間がどれくらいかかったのかを計測する3つの方法について学びます.
9-2-1. timeコマンドによる処理時間の計測.
まずは,一番簡単な方法です.javaコマンドの直前に
timeコマンドを置くことで,処理時間を計測できるようになります.
以下のように実行し,結果が得られます.
$ java StringSearcher string1 ring
"string1".contains("ring"): true
$ java StringSearcher string1 ring
"string1".contains("ring"): true
real 0m0.123s
user 0m0.106s
sys 0m0.026s
realで表される時間が,
プログラムの呼び出しから終了までにかかった実時間(秒)を表しており,
userがプログラム自体に要した処理時間(秒)です.
これは,ユーザCPU時間と呼ばれます.
最後のsysはシステム時間と呼ばれる時間で,OSが実際に処理を行った時間を表しています.
この計測方法で何度か計測してみましょう.
9-2-2. ミリ秒単位の処理時間の計測.
先ほどのtimeコマンドを使った方法では,
Java仮想マシンの起動時間も含めたプログラム全体の実行時間を測定することしかできません.
より細かく,例えば,メソッド単位での処理時間を計測したい場合はどのようにすれば良いのでしょうか.
void measureTime(){
Long startTime = System.currentTimeMillis();
// 処理時間を計測したい処理を実行する.
this.run();
Long elapsedTime = System.currentTimeMillis();
System.out.println((elapsedTime - startTime) + " ms");
}
それには,System.currentTimeMillis()というメソッドを利用します.
このメソッドは,現在時刻をLong型で返しています.
精度はミリ秒($1ms=1\times 10^{-6}s$)です.
そこで,ある時点での時刻を取得しておき,計測したい処理を実行します.
計測したい処理が終わったあと,再度時刻を取得し,その時刻の差を求めることで,
処理時間が計測できるようになります.
9-2-3. ナノ秒単位の処理時間の計測.
上記の方法で規模の大きな処理の実行時間は計測できます. しかし,ミリ秒よりも早い時間で終わる処理を計測したい場合はどのようにすれば良いのでしょうか.
void measureNanoTime(){
Long startTime = System.nanoTime();
// 処理時間を計測したい処理を実行する.
this.run();
Long elapsedTime = System.nanoTime();
System.out.println((elapsedTime - startTime) + " ns");
}
それには,System.nanoTimeを利用します.
ナノ秒($1ns=1\times 10^{-9}s$)の単位で現在時刻をLong型で返すメソッドです.
ただし,現在時刻と言っても,我々が認識するような時刻への変換はできません.
返される値は,固定された任意の基準時間からの経過時間であるためです.
一方で,このメソッドが返す精度はナノ秒ですが,値の更新頻度(解像度)はナノ秒であるとは限りません.
近年のJavaでは,このnanoTimeメソッドを使って時間計測を行う方が良いでしょう.
ミリ秒では計測できない処理が多くあるためです.
Long startTime = System.nanoTime(); Long elapsedTime = System.nanoTime(); System.out.println((elapsedTime - startTime) + " ns");
しかし,ナノ秒で計測できるからといって,計測した時間が絶対的に正しいわけではありません.
ナノ秒の計測自体にも時間がかかっているためです.
左のプログラムを実行すると,何が計測できるでしょうか.
1回のnanoTimeの実行に要する時間が計測できます.
今,手元のPCで計測すると,20,000 nsから35,000 nsの範囲に結果が散らばります.
つまり,nanoTimeを実行するのに,これくらいの時間を要するわけです.
ですから,これよりも小さい値は誤差として扱う必要があることも合わせて覚えておいてください.
9-2-4.
作成したcontainsとString型のcontainsの実行速度比較.
では,このナノ秒の計測方法を使って,我々の作成したcontains
とString型に定義されているcontains
メソッドの処理速度をそれぞれ測定し,違いを比べてみましょう.
9-3. ボイヤ・ムーア法による文字列検索
9-3-1. ボイヤ・ムーア法のアルゴリズム
ボイヤ・ムーア法は文字列探索アルゴリズムの中で洗練された方法の一つです. Boyer と Mooreに寄って提案された方法であり,BM法と略される場合もあります.
9-1で作成した単純な文字列検索では,一致しなかった場合, 1文字だけずらして,再度検索を行いました. ボイヤ・ムーア法では一致しなかった場合, 検索対象文字列の文字が照合文字列中に現れるかどうかを調べて,一気に何文字もずらして検索を行います.
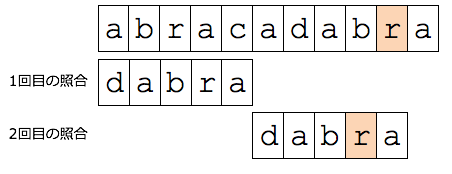
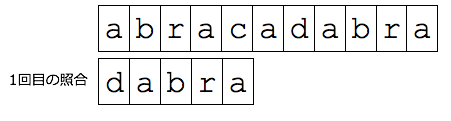 例を挙げて,ボイヤ・ムーア法の説明をします.
右図のように,
例を挙げて,ボイヤ・ムーア法の説明をします.
右図のように,"abracadabra"と"dabra"
を比較するとき,"dabra"の右端の文字から照合を始めます.
'c'と'a'を比較した結果,一致しないことがわかります.
ここで,一致しなかった文字'c'が照合文字列に含まれるかを確認します.
照合文字列には,'c'という文字は含まれていません.
そのため,いくら'c'を元に比較を行ってもマッチしません.
そこで,一気に5文字("dabra"の長さ)ずらします.
 2回目の照合も,1回目と同じように照合文字列の右端から比較を行います.
さて,比較するのは,
2回目の照合も,1回目と同じように照合文字列の右端から比較を行います.
さて,比較するのは,'r'と'a'です.
これも一致しません.しかし,一致しなかった文字'r'
は照合文字列に含まれていますので,1文字しかずらせません.
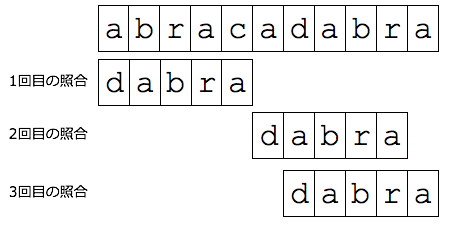 さて,次の照合でも同じように,照合文字列の右端から比較を行います.
この場合,無事にマッチすることが確認できます.
さて,次の照合でも同じように,照合文字列の右端から比較を行います.
この場合,無事にマッチすることが確認できます.
このように,一致しなかった場合でも,一致しないという情報を使って最大限に検索回数を減らすのが ボイヤ・ムーア法です.長い検索対象文字列から長い照合文字列を見つけ出す時に, 特に有効に働くアルゴリズムです.
9-3-2. ボイヤ・ムーア法の実装
では,実際に作成してみましょう.ただし,このアルゴリズムを実現できた人は成績に加点を行いますが, このアルゴリズムが実現できなくても成績が下がることはありません.
このアルゴリズムを実現する時には,一致しなかった場合,何文字ずらすのかの記録が必要です.
ずらすための表 skipTable を作成しましょう.skipTableは
Mapで作成しましょう.キーはCharacter型,
バリューはInteger型としましょう.
照会文字列の文字を順に確認して,
検索対象文字列に,その文字が現れて一致しなかった時に何文字ずらせば良いかを考えましょう.
これは,単純に,その文字から行末までの距離を入れれば良いです.
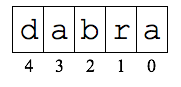 右図のように,照会文字列が
右図のように,照会文字列が "dabra"の場合,前から順に,'d'
は4文字ずらし,'a'は3文字,'b'は2文字,'r'は1文字,
最後の'a'は0文字ずらせば良いです.ただし,2文字目と最後の文字
'a'は一致しますが,最後の文字でずらす数を上書きすると良いでしょう.
また,この照会文字列に現れない文字の場合は,この文字列の長さ分だけずらせば良いです
なお,比較対象の文字が照会文字列に現れない場合の,ずらす数を取得する方法を考えましょう.
この場合,照会文字列の長さ分だけずらします.
下のプログラムの18行目で,このずらす数をあらかじめMapに入れています.
もちろん,list2.size()を取得しても良いのですが,
あらかじめMapにlist2.size()の値を入れておくことで,
ずらす数を調べたい時は,Mapを見るだけで良いようにしています.
この例のように,Mapに与えるキーはnullであっても問題ありません.
Boolean bmMethod(List<Character> list1, List<Character> list2){
// 上記の説明を参考に,skipTableを作成する.
Map<Character, Integer> skipTable = buildSkipTable(list2);
for(Integer i = 0; i < list1.size(); ){
Boolean foundFlag = true;
for(Integer j = list2.size() - 1; j >= 0; j--){
Integer index = i + j; // list1のインデックス.
// indexがlist1の範囲を超えていないかを確認する.
// list1.get(index) と list2.get(j) を比較して,一致
// しなければ,skipTableからずらす数を取得してiに加算する.
// foundFlagもfalseにしてから内側のループを抜ける.
}
}
}
Map<Character, Integer> buildSkipTable(List<Character> list2){
Map<Character, Integer> skipTable =
new HashMap<Character, Integer>();
skipTable.put(null, list2.size());
for(Integer i = 0; i < list2.size(); i++){
skipTable.put(list2.get(i), list2.size() - i - 1);
}
return skipTable;
}
次に,検索対象文字列と照会文字列の比較を行いましょう. 照会文字列の取得は,左端から行うことに注意しましょう. また,位置を大きくずらした時に,範囲を超えないことに注意しましょう. ヒントは左のプログラムに示しています.
完成すれば,9-2-4で行った比較に加えて, ボイヤ・ムーア法での比較の処理時間も調べてみましょう.
9-3-3. ボイヤ・ムーア法の改良
9-3-2までの実装で多くの文字列の検索ができるようになります.
しかし,特定の文字列の場合,検索が失敗します.
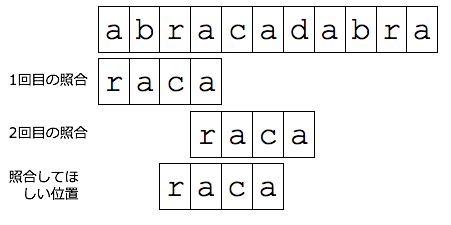 例えば,検索対象文字列が,
例えば,検索対象文字列が,'abracadabra'で,照合文字列が'raca'
の場合,次のような問題が起こります.
1回目の照合のとき,一番最後の文字,'a'は一致します.
次の照合の'r'と'c'は一致しません.
skipTableに入っている'r'のずらす数は3ですので,
2回目の照合では,右図の「2回目の照合」の位置に照合文字列が置かれます.
これだと,'raca'の検索に失敗します.
本来,照合してほしい位置は,右図にある通りです.
原因は,ずらす位置の開始位置が間違っていたためです.
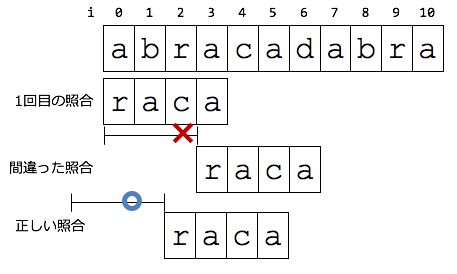 9-3-2での照合は,右図の間違った照合の処理を行っています.
ずらす位置の開始位置が,×のように,照合の開始位置からだと,一度,照合時に比較された文字は
2度と照合されることはありません.
ずらす位置の開始位置は,一致しなかった文字にすると,
右図の○のようにこのような文字列でも無事に照合できるようになります.
9-3-2での照合は,右図の間違った照合の処理を行っています.
ずらす位置の開始位置が,×のように,照合の開始位置からだと,一度,照合時に比較された文字は
2度と照合されることはありません.
ずらす位置の開始位置は,一致しなかった文字にすると,
右図の○のようにこのような文字列でも無事に照合できるようになります.
では,どのようにずらせば良いのかを考えましょう.
今では,単純にiにskipを加えています.
単純に加えるのではなく,skipから,照合に成功した文字数を引いた数を
skipとしましょう.照合に成功した文字数は,list2.size() - j - 1
で得られます.
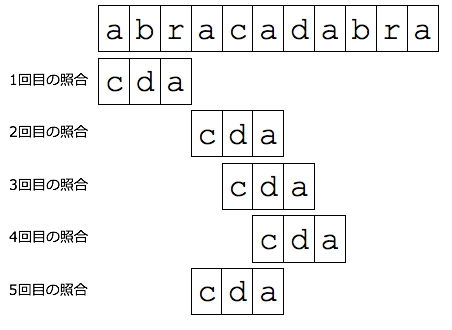 しかし,この場合もまだ問題が起こります.無限ループの可能性が出てきます.
しかし,この場合もまだ問題が起こります.無限ループの可能性が出てきます.
'abracadabra'から'cda'を検索しましょう.
右図のように,5回目の照合時に左に戻ってしまいます.この場合は,1文字だけずらすようにしましょう.
skipの値が0以下であれば,skipの値を
1にすることで対応します.
Integer index = i + j; // list1のインデックス. // indexがlist1の範囲を超えていないかを確認する. // list1.get(index) と list2.get(j) を比較して,一致しなければ, // skipTableからずらす数を取得し,skipとする. // skip から 照合に成功した文字数(list2.size() - j - 1)を引き. // skip とする.次に,skipの値を調べ,0以下であれば,skipを1にする. // iにskipを加算し,新たなiとする. // foundFlagもfalseにしてから内側のループを抜ける.
以上のことから,9-3-2に示したプログラムの 7行目から11行目は左のプログラムのコメントに置き換えて,プログラムを修正しましょう.
10. ファイル内の検索を正規表現で行えるようにする.
10-1. 正規表現とは何か.
正規表現(Regular expression)とは,複数の文字列表現を一つの文字列で表現するための表現方法の一つです. 正規表現は,エディタの文字列検索や,あるフォーマットに合致するかの検証, パターン検索分野で使われています.
正規表現は特殊な意味を持つ記号を含んだ文字列として表されます.
例えば,郵便番号を正規表現で表す場合を考えてみましょう.
郵便番号には,603-8555や,100-0001 のような様々な値が入りますが,基本的には,
3桁の数値,ハイフン,4桁の数値で表現できます.
これを正規表現で表した場合,"[0-9]{3}-[0-9]{4}"で表現できます.
そして,ある文書中に,具体的な郵便番号(例えば603-8555など)が含まれていて, 上記の正規表現で検索した時,その郵便番号が検索結果に含まれるようになります. この時,検索結果の文字列は,与えられた正規表現にマッチしたと言います.
正規表現では,次の表に示すように特別な意味を持つ文字が存在します.
()- カッコ内の正規表現をグループ化して1文字として扱います. また,多くの実装で後から参照できるようになっています.
[...]-
カッコ内に含まれる1文字にマッチします.
[0123456789]は0,1,...,9のいずれかの場合,マッチします. 連続する場合は,[a-z]のように表せます. [^...]-
[...]に含まれない文字1文字にマッチします.[^0-9a-zA-Z]は記号の文字1文字にマッチします. {n}-
直前の正規表現がn回の繰り返された時にマッチします.
[0-9]{4}は4桁の数字の文字列にマッチします. |-
前後の文字列のどちらがきてもマッチします.
例えば,gr(a|e)yは,grayとgreyにマッチします. ?-
直前の表現が0個か1個あることを示します.
例えば,behaviou?rは,behaviorとbehaviourにマッチします. *-
直前の表現が0個以上あることを示します.
例えば,yaho*は,yah,yahooooooyahooなどにマッチします. +-
直前の表現が1個以上あることを示します.
例えば,go+dは,god,good,goooodなどにマッチしますが,gdにはマッチしません. ^-
この文字自体が行の先頭にマッチします.
^This is a penという正規表現はこの文章自体が行頭にある時のみマッチします. $-
この文字自体が行の最後にマッチします.
bye$という正規表現はbyeが行末にある時のみマッチします. \\-
バックスラッシュ(
\)自身にマッチします.
実際には,もっと複雑なルールがありますが,この程度を知っておけば入門として十分でしょう. 実際に使うときにインターネット上などで調べてください.
10-2. Javaでの正規表現の扱い方.
10-2-1. Javaでの正規表現の扱い方.
Javaで正規表現を使うとき,java.util.regex
パッケージに所属する型を利用します.
regexは Regular Expression の略で,正規表現を省略して書く時によく用いられる表現です.
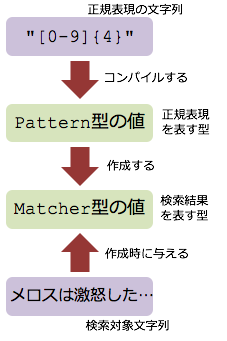 Javaで正規表現を扱うには,2つの型を使わなければいけません.
Javaで正規表現を扱うには,2つの型を使わなければいけません.
PatternとMatcherです.
Pattern型は正規表現そのものを表す型です.
一方のMatcher型は,検索結果を表す型です.
検索結果のうち,マッチしたか否かはもちろん,どの位置にマッチしたか,
何度マッチしたかなどを取得できます.
では,実際にプログラムコードで見てみましょう.
下のプログラムがJavaで正規表現を扱う一連の流れです.
2行目は,検索対象の文字列がString型のtarget
に代入されたことを表しています.
次の3行目は,正規表現がString型のregex
に代入されています.
そして,4行目で右図のコンパイルを行い,Pattern型の値を取得しています.
Pattern型の値であるpatternを作成する部分は,
今までのように,newを使っていません.
さらに,Patternという型に対してメソッドを呼び出しています.
// 検索対象文字列は与えられるものとする.
String target = ....
String regex = "[0-9]{4}";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(target);
if(matcher.find()){
System.out.println("見つかった");
}
実は,メソッドには,値(変数)に対して呼び出すものと,型に対して呼び出すものの2種類が存在します.
フィールドも同様です.例えば,System.outはSystem型に属する変数
outの参照を表しています.
Objects.equalsも同様です.そのようなメソッドがある,
ということを知っておけばここでは十分でしょう.なお,このようなメソッドのことを
スタティックメソッド(static method)と呼びます.勘の良い人は気付くかもしれませんが,
mainメソッドもスタティックメソッドの一つです.
では,話を戻して,4行目のPattern型の値を取得する部分の解説です.
Pattern型のメソッドであるcompileを呼び出せば,
コンパイル済みのPattern型の値が取得できます.その値を変数に代入しているのが4行目です.
続いて5行目でMatcher型の値を取得しています.
Matcher型の値はPattern型の値に所属するメソッド,
matcherから取得します.
メソッドが型に属しているのか,値(変数)に属しているのかをしっかりと区別しましょう.
6行目で検索が成功したか否かを判定しています.find
メソッドは正規表現にマッチすれば,trueを返すメソッドです.
10-2-2. grepオプションを正規表現で受けられるようにする.
では,10-2-1で学んだ内容を,FileFinder
に組み込んでみましょう.
grepオプションで指定する文字列を正規表現であるとして検索してみましょう.
$ java FileFinder . -grep 'ゴーシュ'
file.txt
$ java FileFinder . -grep '[0-9]{4}'
file.txt
例えば,左のような指定で,5桁の数値を含むテキストファイルを検索できることを確認してみましょう. 通常の文字列も正規表現の1表現です. 今までの検索方法でも同じような結果が帰ってくることを確認しましょう.
grepの処理部分を10-2-1
のプログラムを元に書いてみましょう.
本日のまとめ
今日,学んだ内容は次の通りです.
- 文字列高速検索アルゴリズム
- 単純な文字列検索
- ボイヤ・ムーア法
- 正規表現
- 正規表現とは何か.
- Javaでの正規表現の取り扱い方法.
- 処理時間の計測方法.
Findプログラムのまとめ
学んだ内容のまとめ
このFindプログラムでは,以下の内容を学びました.
- 再帰呼び出し.
- コマンドライン引数の扱い方.
- Javaでのファイル,ディレクトリの扱い方.
- Javaでの入出力の取り扱い方法.
- 例外機構
- 文字列検索アルゴリズム
- 処理時間の計測方法.
提出するファイルについて
StringSearcherについて
今日の9で作成したStringSearcherを提出してください.
期限は今日の24:00までです.
提出場所は,Moodle上の指示された場所とします.
ソースファイル(StringSearcher.java)を提出してください.
ただし,マークの部分は, 着手していると加点対象にはなりますが,完成していなくても減点対象にはなりません. それ以外の部分をしっかりと作り込んでください.
Findプログラムについて
Findプログラムで作成したプログラムを提出してください. 提出期限は次回授業の前日24:00までとします. 提出場所は,Moodle上の指示された場所とします. 以下の手順を行って,zipファイルを提出してください.
ただし,StringSearcherと同じく,
マークの部分は,
着手していると加点対象にはなりますが,完成していなくても減点対象にはなりません.
それ以外の部分をしっかりと作り込んでください.
- まず,ディレクトリを作成し,そのディレクトリの名前を6桁の学生証番号にしてください.
- すべてのプログラムに自身の学生証番号,名前をコメントに入れてください.
- 次に,この回までに作成したプログラム,データをそのディレクトリに入れてください.
- そのディレクトリをzip圧縮してください.zip圧縮後のファイル名を「学生証番号.zip」にしてください.
提出するファイルは次の通りです.もし,パッケージ宣言している場合は, その部分をコメントアウトし,パッケージ宣言はしないようにしてください.
FileFinder.javaArguments.java