2016-12-01, 2016-12-08 第10, 11回目 応用1
本日のテーマ
これからの2週は,以下の8つのプログラムを作成する時間とします. 逆ポーランド記法の計算機までを必須とします.
- コマンドラインで受け取った文字列が特定の文字列かを確認する
yesコマンド:特定文字列を繰り返す.sortコマンド:ファイルの内容をソートする.tacコマンド:ファイルの内容を逆順に表示する.freqコマンド:与えられたテキストファイルに現れる単語の頻度を求める.tailコマンド:与えられたテキストファイルの最後の数行を出力する.- 逆ポーランド記法の計算機
- 2つの文字列間の類似度・距離
2つの文字列間の類似度・距離は今は書けなくても問題ありませんが, 3年生終了時点では書けるようになっていてもらいたいレベルです.
応用1 プログラム集の作成
1. コマンドラインで受け取った文字列が特定の文字列かを確認する
コマンドラインで渡された文字列が特定の文字列("KSU_AP")であれば,
「渡された文字列は”KSU_AP”です」と出力してください.
特定の文字列でなければ,「渡された文字列は”KSU_AP”ではなく,”(実際に渡された文字列)”です.」 と出力するプログラムを作成してください.
コマンドライン引数で複数の文字列が渡された場合,全ての文字列に対して判定を行ってください.
クラス名は,ComparingStringとしてください.
実行例
$ java ComparingString hoge KSU KSU_AP KSU_AP2
渡された文字列は "KSU_AP"ではなく"hoge"です.
渡された文字列は "KSU_AP"ではなく"KSU"です.
渡された文字列は "KSU_AP" です.
渡された文字列は "KSU_AP"ではなく"KSU_AP2"です.
参考
2. yesコマンド:特定文字列を繰り返す.
無限にyを出力するコマンドyesを作成してください.
もし,コマンドライン引数に何か文字が指定された場合,その文字を無限回出力してください.
終了するときは,Ctrl-C で終了してください.
クラス名は,Yesにしましょう.
実行例
$ yes no
no
no
... 途中省略
^C // Ctrl-C を入力し,強制終了
$ java Yes
y
y
... 途中省略
^C // Ctrl-C を入力し,強制終了
$ java Yes yes
yes
yes
... 途中省略
^C // Ctrl-C を入力し,強制終了
参考
3. sortコマンド:ファイルの内容をソートする.
コマンドライン引数で与えられたファイルの内容を行単位でソートして出力するコマンド Sorterを作成してください.
実行例
$ cat string.txt
String class represents character strings.
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Strings are constant; their values cannot be changed after they are created.
String buffers support mutable strings.
Because String objects are immutable they can be shared.
$ sort string.txt
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Because String objects are immutable they can be shared.
String buffers support mutable strings.
String class represents character strings.
Strings are constant; their values cannot be changed after they are created.
$ java Sorter string.txt
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Because String objects are immutable they can be shared.
String buffers support mutable strings.
String class represents character strings.
Strings are constant; their values cannot be changed after they are created.
$ cat string2.txt
abra
cada
bra
abc
def
$ java Sorter string2.txt
abc
abra
bra
cada
def
string.txtが必要であればリンクをクリックし,ダウンロードしてください.
ヒント
- まず,ファイルから1行ずつ文字列を読み込みましょう.
- 読み込んだ文字列を
ArrayListに追加しましょう. Collections.sortにArrayListの実体を渡し,ソートしましょう.ArrayListを順に出力しましょう.
Listのソート
配列のソートはArrays.sortメソッドで行いました.
同じように,Listをソートするメソッドも標準的に用意されています.Collectionsを
利用すると,Listの内容を辞書順に並び替えられます.
なお,Collectionsを利用するときは,java.util.Collectionsのインポートが必要です.
ArrayList<String> list = // ArrayListの実体を作成する.
Collections.sort(list); // => list の内容が要素を並び替えたものになっている.
参考
4. tacコマンド:ファイルの内容を逆順に表示する.
ファイルを逆順に表示するコマンドtacを作成してください.
複数のファイルが指定された場合,各ファイルの内容を逆順に表示してください.
クラス名は Tac(catの逆)とします.
実行例
$ cat sample2.txt
ABCDEFG
1234567890
$ java Tac sample2.txt
1234567890
ABCDEFG
$ cat sample3.txt
abracadabra
$ java Tac sample3.txt
abracadabra
参考
5. freqコマンド:与えられたテキストファイルに現れる単語の頻度を求める.
与えられたテキストファイル(英文)の中に現れる単語の頻度を求めるプログラムを作成してください. 単語の頻度とは,その単語が文書中に何回現れたかを示す値です.
実行例
$ cat string.txt
String class represents character strings.
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Strings are constant; their values cannot be changed after they are created.
String buffers support mutable strings.
Because String objects are immutable they can be shared.
$ java Frequencies string.txt
All: 1
"abc",: 1
constant;: 1
be: 2
string: 1
instances: 1
.... 以下略
string.txtが必要であればリンクをクリックし,ダウンロードしてください.
参考
6. tailコマンド:与えられたテキストファイルの最後の数行を出力する.
与えられたテキストファイルの最後の数行を出力するプログラムを作成してください. 最後の数行もコマンドラインで与えられるものとします. また,数値は必ず正の値が与えられるものと考えて構いません.
実行例
$ cat string.txt
String class represents character strings.
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Strings are constant; their values cannot be changed after they are created.
String buffers support mutable strings.
Because String objects are immutable they can be shared.
$ tail -1 string.txt
Because String objects are immutable they can be shared.
$ java Tail 2 string.txt
String buffers support mutable strings.
Because String objects are immutable they can be shared.
$ java Tail 10 string.txt
String class represents character strings.
All string literals in Java programs, such as "abc", are implemented as instances of this class.
Strings are constant; their values cannot be changed after they are created.
String buffers support mutable strings.
Because String objects are immutable they can be shared.
string.txtが必要であればリンクをクリックし,ダウンロードしてください. 総行数よりも大きな値が指定された場合でもエラーが発生しないようにしてください.
なお,tailコマンドのオプションで指定した-1は負の値を表しているのではなく、
1という数値を表しています。1に付けられている-はオプションを表す記号であり,
負の値を表す記号ではないことに注意してください.
ヒント
最後の数行がどの行から開始すれば良いのかは最初はわかりません.
そのため,まずは,全ての行を ArrayListに保存しましょう.
全ての行を保存すると,必要な行を出力するためのインデックスは(全行数-指定行数)から始めれば良いとわかります. そこから最終行までを出力してください.
参考
7. 逆ポーランド記法の計算機
逆ポーランド記法での計算機を作成しましょう.
逆ポーランド記法とは,後置記法とも呼ばれます.
中置記法と呼ばれる通常の記法は,1 + 2 ですが,これを逆ポーランド記法で書くと,1 2 +となります.
コマンドライン引数で,このような計算式を受け取り,計算結果を出力するプログラムを書いてください.
数値は全てDoubleで扱ってください.
クラス名は,ReversePolishNotationCalculatorとしましょう.
実行例
$ java ReversePolishNotationCalculator "1 2 +"
3.000000 (1 2 +)
$ java ReversePolishNotationCalculator "1 2 +" "3 4 +"
3.000000 (1 2 +)
7.000000 (3 4 +)
$ java ReversePolishNotationCalculator "1 2 + 9 6 - *"
9.000000 (1 2 + 9 6 - *)
引数で受け取った文字列を逆ポーランド記法で書かれた数式と捉えて,計算してください. 計算結果を出力後,同じ行に計算の元となった数式を1行で出力してください. なお,演算子と数値の間は必ずスペースで区切られているという前提で計算してください.
複数の計算式が指定された場合,一つの数式を1行で出力するようにしてください.
なお,逆ポーランド記法で与えた計算式を中置記法で表すと,次の通りです.
1 2 +→1 + 23 4 +→3 + 41 2 + 9 6 - *→(1 + 2) * (9 - 6)
ヒント
与えられた文字列をスペースで区切って,最初から順に処理していきましょう.
今,見ている文字列(スペースを含まない)が数値の場合は,Listに追加しましょう.
数値でなく演算子の場合は,Listの後ろから2つの数値を取り出し(Listから削除し),
演算子に従った処理を行って,計算結果をListに追加しましょう.
上記の繰り返しで逆ポーランド記法の計算機は実現できます. 上記の処理内容は,実は,スタック(Stack)そのものです.
参考
8. 2つの文字列間の類似度・距離
コマンドライン引数で与えらえた2つの文字列の類似度を次の5つの方法で求めてください.
- Simpson係数
- Jaccard係数
- Dice係数
- コサイン類似度
- 編集距離(Levenshtein距離)
クラス名は,StringSimilaritiesとしてください.
Simpson係数(Simpson Index)
2つの集合があったとき,下図のように,両方の集合の要素数のうち短い方で積集合を割ったものが Simpson係数です.
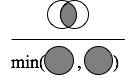
文字列(String型)は,Character型の集合と考えられます.
そのため,2つの文字列それぞれの長さ,積集合を計算できれば,Simpson係数が求められます.
Jaccard係数(Jaccard Index)
2つの集合があったとき,右図のように積集合を和集合で割った値がJaccard係数です.
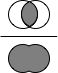
文字列(String型)は,Character型の集合と考えられます.
そのため,2つの文字列の積集合,和集合を計算できれば,Jaccard係数が求められます.
Dice係数(Dice Index)
2つの集合があったとき,下図のように積集合の2倍の数を,集合の要素数の和で割ったものが Dice係数です.
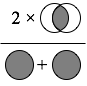
文字列(String型)は,Character型の集合と考えられます.
そのため,2つの文字列それぞれの長さ,積集合を計算できれば,Dice係数が求められます.
コサイン類似度(Cosine similarity)
2つのベクトルを考え,そのベクトルの成す角のコサインがコサイン類似度です. 文字列を文字を要素とするベクトルと考え,2つの文字列から2つのベクトルを構築します.
2つのベクトル $\vec v_1$,$\vec v_2$があるとき,2つのベクトルのコサインは, $\cos \theta =(\vec v_1 \cdot \vec v_2)/(|\vec v_1||\vec v_2|)$で求められます. 文字列から,文字の頻度を計算し,それをベクトルとして扱えば,コサイン類似度が求められます.
"value1"と"value2" の2つの文字列を考えてみましょう.
2つの文字列からそれぞれベクトルを作成して,$\vec{v_1}= { 1,1,1,1,1,1,0 }$,
$\vec{v_2} = {1,1,1,1,1,0,1}$とします.
ベクトルの各要素は, {'v', 'a', 'l', 'u', 'e', '1', '2'}としています.
$\cos\theta$を求める式に当てはめると,$\frac{5}{\sqrt{6}\sqrt{6}}$となり,
"value1"と"value2" のコサイン類似度は,0.83333…と計算できます.
編集距離(Edit Distance; Levenshtein Distance)
編集距離(Levenshtein距離)とは,2つの文字列がどの程度異なっているかを表す距離のことを指します. 一方の文字列から,もう一方の文字列に変更するまでに必要な,1文字の挿入,削除,置換の最小手順で距離を定義しています.
例えば,次の手順を行えば,"distance"から "similarity"に変更できます.
この場合,8回の手順で変更できたため,編集距離は 8 となります.
"distance""sistance".(1文字目のdをsに置換)"simtance".(3文字目のsをmに置換)"simiance".(4文字目のtをiに置換)"similance".(5文字目にlを追加)"similarce".(7文字目のnをrに置換)"similarie".(8文字目のcをiに置換)"similarit".(9文字目のeをtに置換)"similarity".(10文字目にyを追加)
実際に長さ$n$と$m$の文字列$S_n, S_m$間の編集距離を計算するには, $(n+1)(m+1)$の表が必要になります. この表のことを編集グラフ(Edit graph)と呼びます.
- 表の初期化処理は次の通りです.
- $n=0$の$i$列目に$i$を代入します.
- $m=0$の$j$行目に$j$を代入します.
- 結果として,一番上の行,一番左の列のみに数値が入れられた表が得られます. 値は,左(下)になるにつれ1ずつ増えていきます.
- 表の空いている場所に次のルールに従って値を埋めていきます.
- 注目しているセルの上,左のセルの値に1を足し,コストとします.($d_1$, $d_2$とします)
- $S_n$の$i$番目の文字と$S_m$の$j$番目の文字を比較します. 異なっていればコストを1,同じであれば,コストを0とします.
- 注目しているセルの左上のセルに,先ほど求めたコストを足します($d_3$とします)
- $d_1$,$d_2$,$d_3$を比べ,一番小さな値を注目しているセルの値として更新します.
- 上記をすべてのセルに対して行います.
- すべての値が埋められた表が得られたとき,一番右下の値が編集距離です.
表の作成イメージは以下の通りです. まず,0行目,0列目を埋めます. その後,空いているセルを左上から順に埋めていきます. 当該セルの値は,上,左,左上の3つのセルの値から求められます. 基本的には,上,左,左上のセルの値に1を加算した値を求めます. ただし,それぞれの文字列の対応する文字が一致した場合,左上のセルの値をそのまま利用します(1の加算は行いません). その上で,3つの数値を比較し,一番小さな値がそのセルの値として表が更新されます.

実行例
$ java StringSimilarity distance similarity
simpson(distance, similarity)=0.500000
jaccard(distance, similarity)=0.333333
dice(distance, similarity)=0.500000
cosine(distance, similarity)=0.530330
edit_distance(distance, similarity)=8
$ java StringSimilarity android ipodtouch
simpson(android, ipodtouch)=0.428571
jaccard(android, ipodtouch)=0.272727
dice(android, ipodtouch)=0.428571
cosine(android, ipodtouch)=0.502519
edit_distance(android, ipodtouch)=7
ヒント
文字列から重複なしの文字の集合を取得する.
以下のプログラムで,文字列から重複なしの文字の集合を取得できます.
ArrayList<Character> getList(String item){
ArrayList<Character> list = new ArrayList<Character>();
for(Integer i = 0; i < item.length(); i++){
Character c = item.charAt(i);
if(!list.contains(c)){
list.add(c);
}
}
return list;
}
表の作成
表の作成には,Table.javaを利用してください.
Table.javaは左の1行目のように,どんな型を入れるTableにするか,
何行×何桁のTableにするかを決めます.
そして,値を設定するには,setメソッドに値とx, yのインデックスを指定します.
値を取得するときは,x, yのインデックスを指定して取得します.
Table<String> table = new Table<String>(41, 21);
table.set("X", 0, 1);
String item = table.get(0, 1);